SQL - MySQL 实现分库分表详解
SQL - MySQL 实现分库分表详解
一、为什么要分库分表
如果一个网站业务快速发展,那这个网站流量也会增加,数据的压力也会随之而来,比如电商系统来说双十一大促对订单数据压力很大,Tps十几万并发量,如果传统的架构(一主多从),主库容量肯定无法满足这么高的Tps,业务越来越大,单表数据超出了数据库支持的容量,持久化磁盘IO,传统的数据库性能瓶颈,产品经理业务·必须做,改变程序,数据库刀子切分优化。数据库连接数不够需要分库,表的数据量大,优化后查询性能还是很低,需要分。
二、什么是分库分表
分库分表方案是对关系型数据库数据存储和访问机制的一种补充。
- 分库:将一个库的数据拆分到多个相同的库中,访问的时候访问一个库;
- 分表:把一个表的数据放到多个表中,操作对应的某个表就行。
三、分库分表的几种方式
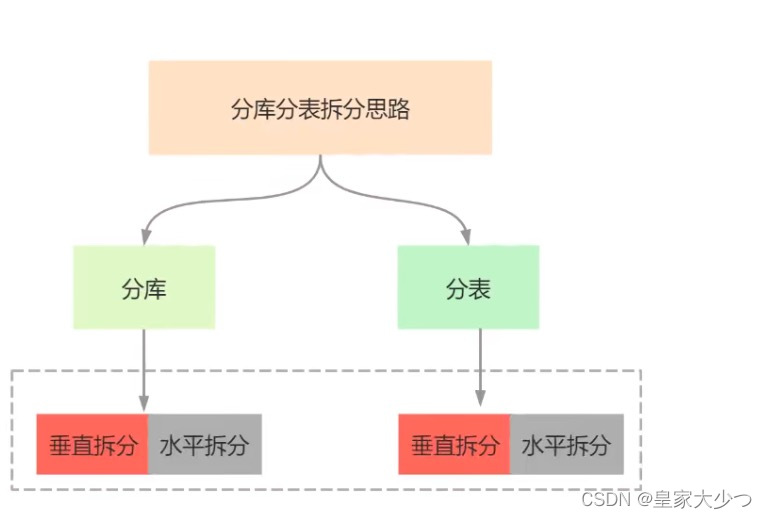
1. 垂直拆分
数据库垂直拆分
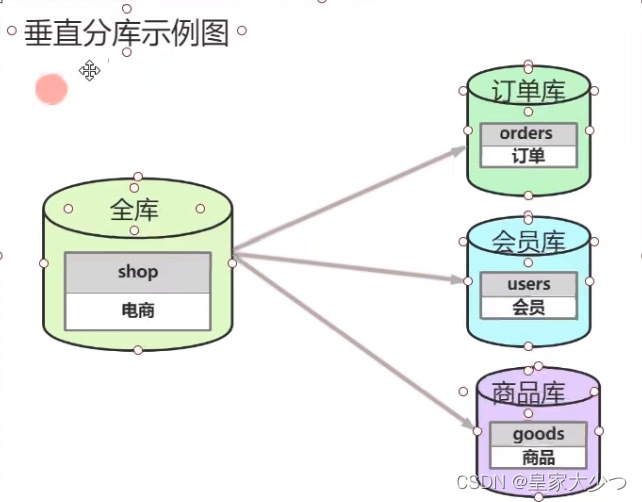
根据业务拆分,如图,电商系统,拆分成订单库,会员库,商品库。
表垂直拆分
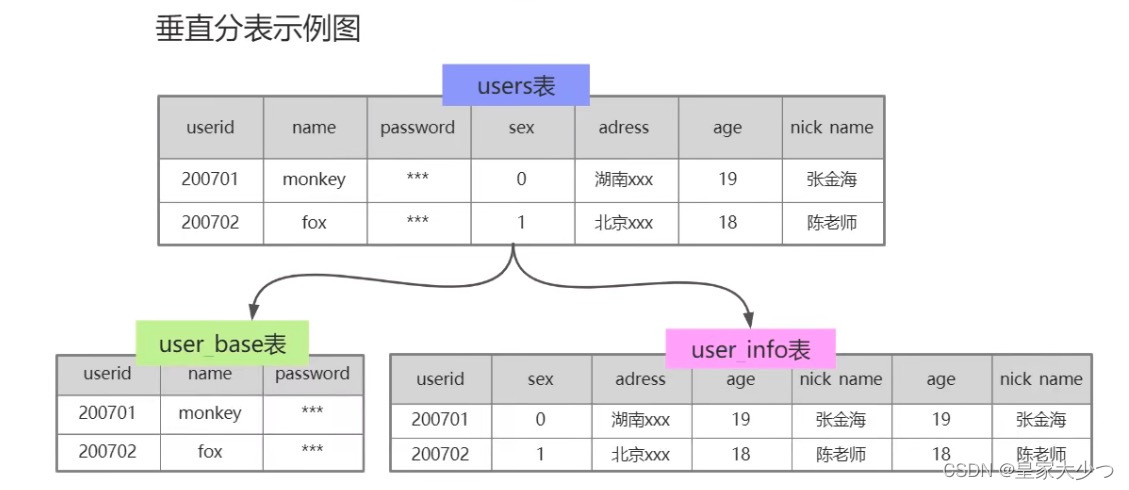
根据业务去拆分表,如图,把user表拆分成user_base表和user_info表,use_base负责存储登录,user_info负责存储基本用户信息
垂直拆分特点
- 每个库(表)的结构都不一样
- 每个库(表)的数据至少一列一样
- 每个库(表)的并集是全量数据
垂直拆分优缺点
优点:
- 拆分后业务清晰(专库专用按业务拆分)
- 数据维护简单,按业务不同,业务放到不同机器上
缺点:
- 如果单表的数据量,写读压力大
- 受某种业务决定,或者被限制,也就是说一个业务往往会影响到数据库的瓶颈(性能问题,如双十一抢购)
- 部分业务无法关联join,只能通过java程序接口去调用,提高了开发复杂度
2. 水平拆分
数据库水平拆分
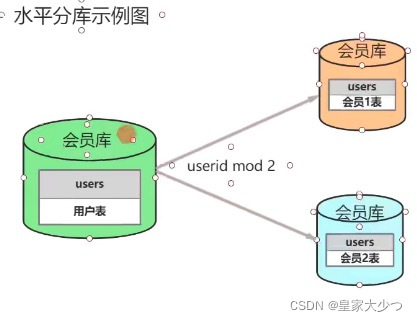
如图,按会员库拆分,拆分成会员1库,会员2库,以userId拆分,userId尾号0-5为1库 6-9为2库,还有其他方式,进行取模,偶数放到1库,奇数放到2库
表水平拆分
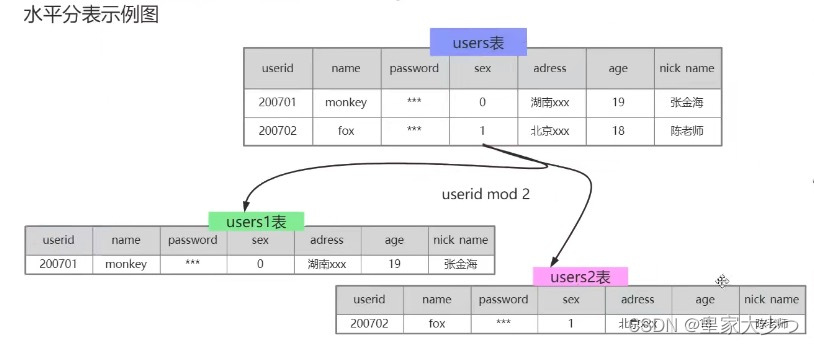
如图把users表拆分成users1表和users2表,以userId拆分,进行取模,偶数放到users1表,奇数放到users2表
水平拆分的其他方式
- range来分,每个库一段连续的数据,这个一般是按比如时间范围来的,但是这种一般较少用,因为很容易产生热点问题,大量的流量都打在最新的数据上了,优点:扩容的时候,就很容易,因为你只要预备好,给每个月都准备一个库就可以了,到了一个新的月份的时候,自然而然,就会写新的库了 缺点:大部分的 请求,都是访问最新的数据。实际生产用range,要看场景,你的用户不是仅仅访问最新的数据,而是均匀的访问现在的数据以及历史的数据
- hash分发,优点:可以平均分配每个库的数据量和请求压力 缺点:扩容起来比较麻烦,会有一个数据迁移的这么一个过程
水平拆分特点
- 每个库(表)的结构都一样
- 每个库(表)的数据都不一样
- 每个库(表)的并集是全量数据
水平拆分优缺点
优点:
- 单库/单表的数据保持在一定量(减少),有助于性能提高
- 提高了系统的稳定性和负载能力
- 拆分表的结构相同,程序改造较少。
缺点:
- 数据的扩容很有难度维护量大
- 拆分规则很难抽象出来
- 分片事务的一致性问题部分业务无法关联join,只能通过java程序接口去调用
四、分库分表带来的问题
- 分布式事务;
- 跨库join查询;
- 分布式全局唯一id;
- 开发成本,对程序员要求高。
分库分表需思考3个问题
事务一致性: 比如更新10张表,最后一张失败,怎样保证事务。
字典表问题: 一般字典表维护在一个库中,分库查询的话影响效率,每个库都存储一份字典表的话,上表面提到的事务一致性问题又会出现。库之间也会过于冗余。
分页查询: 比如查询100到110之间的数据,做法可不是每个库取100110间的数据,再去前10条,而是每个库查询0110间的数据,比如10个库,就会返回 10 * 110条数据,再从这里取100~110间的数据。这里的问题就是如果是 500000~500010的话,返回的数据量就太大了。
五、分库分表技术如何选型
1. 开源框架
目前市面上使用较多的是,mycat及sharding-jdbc。mycat属于中间层代理类中间件、sharding-jdbc属于应用层依赖类中间件。
详细对比
| 主要指标 | Sharding-jdbc | Mycat |
|---|---|---|
| ORM支持 | 适用于任何基于 JDBC 的 ORM 框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template 或直接使用 JDBC | 任意 |
| 事务 | 自带XA、两(三)阶段事务、柔性事务BASE(最终一致) | XA事务 |
| 分库 | 支持 | 支持 |
| 分库 | 支持 | 支持 |
| 开发 | 集成springboot较好,代码入侵中(需要写些配置类等) | 开发成本小,代码入侵小 |
| 所属公司 | 当当网开源,加入apache | 基于阿里Cobar二次开发,社区维护 |
| 数据库支持 | 支持任意实现 JDBC 规范的数据库,目前支持 MySQL,PostgreSQL,Oracle,SQLServer 以及任何可使用 JDBC 访问的数据库 | Mysql、Oracle、 SQL Server、DB2、mongodb |
| 活跃度 | 活跃度高 | 社区活跃度很高,一些公司已在使用 |
| 监控 | 有 | 有 |
| 读写分离 | 支持 | 支持 |
| 资料 | 资料少、github、官网、网上讨论贴 | 资料多,github、官网、Q群、书籍 |
| 运维 | 维护成本低 | 维护成本高 |
| 限制 | 部分JDBC方法不支持、SQL语句限制 | SQL语句限制 |
| 连接池 | 支持任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, HikariCP 等 | 无要求 |
| 配置难度 | 一般 | 复杂 |
- Atlas:不能实现分布式分表,所有的子表必须在同一台DB的同一个database里且所有的子表必须事先建好,Atlas没有自动建表的功能。
- Cobar:必须将拆分后的表分别放入不同的库来实现分布式。
- TDDL:阿里,功能强大,过于复杂,部分开源。需要评估使用情况,防止过剩。
- Mycat :国内开源,从入门到放弃。
- heisenberg:百度开源,相对简单,易于管理。
- Oceanus:功能强大,开源,简化开发和配置成功。但产品还不成熟。
- vitess:google产品,集群基于ZooKeeper管理,通过RPC方式进行数据处理,可支撑高流量,它还添加了一个连接池,具有基于行的高速缓存,重写SQL查询,更安全。
- OneProxy:中国厂商产品,稳定性待确认。
- Sharding-JDBC:当当最新开源,jdbc层面操作。
jdbc 直连层:shardingsphere、tddl
proxy 代理层:mycat,mysql-proxy(360)
2. jdbc直连层
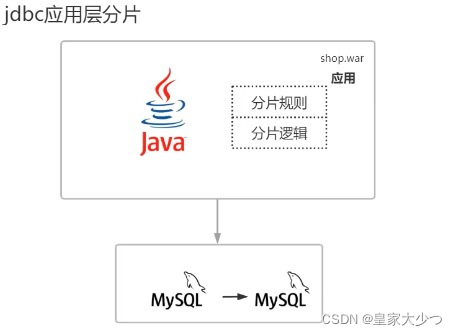
jdbc直连层又叫jdbc应用层,是因为所有分片规则,所有分片逻辑,包括处理分布式事务 所有这些问题它都是在应用层,所有项目都是由war包构成的,所有分片都写成了jar包,放到了war包里面,java需要虚拟机去运行的,虚拟机运行的时候就会把war包里面的字节文件进行classLoder加载到jvm内存中,所有分片逻辑都是基于内存方进行操作的
3. proxy代理层
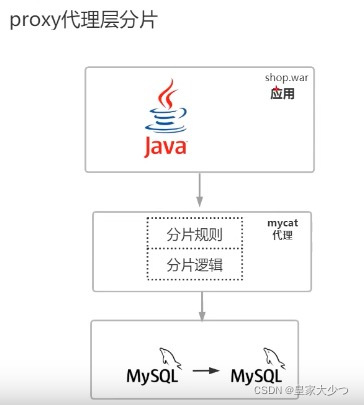
如图,proxy代理层,所有分片规则,所有分片逻辑,包括处理分布式事务都在mycat写好了,所有分片逻辑都是基于mycat方进行操作
jdbc直连层和proxy代理层优缺点
- jdbc直连层性能高,只支持java语言,支持跨数据库;
- proxy代理层开发成本低,支持跨语言,不支持跨数据库。
选型需考虑3个问题:
产品功能和可扩展性:mycat就是不行。就是名气大,已经到头了。Cobar也是可扩展性的问题放弃的
产品是否成熟,或者说可用,比如国内的一般就不考虑了,稳定性是个问题。百度的heisenberg其实不错,但是代码很久没有维护了,社区也不积极,就放弃了。google的vitess也可以 ,但是海外的产品,也放弃了。
实际情况:我们公司是腾讯系的,阿里的TDDL显然不能用了。
引用资料
- https://blog.csdn.net/ahuangqingfeng/article/details/124161107
- https://blog.csdn.net/weixin_43043173/article/details/124897755
- https://blog.csdn.net/u013898617/article/details/79615427
